
OpenAI Releases a Practical Guide to Identifying and Scaling AI Use Cases in Enterprise Workflows
Source: MarkTechPost As the deployment of artificial intelligence accelerates across industries, a recurring challenge for enterprises is determining...
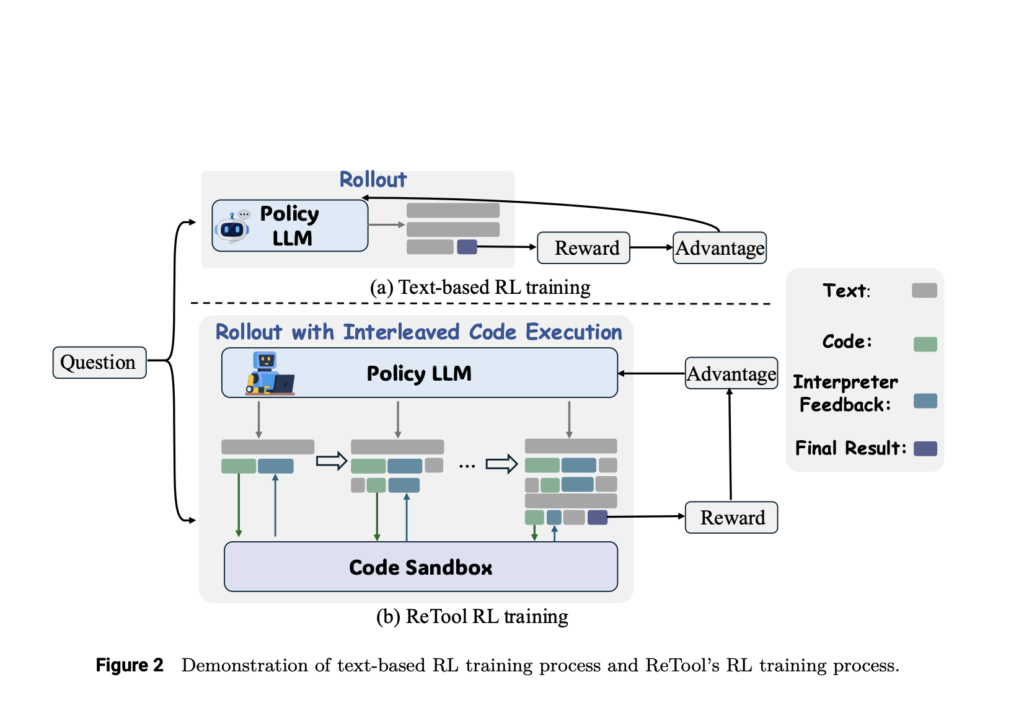
ReTool: A Tool-Augmented Reinforcement Learning Framework for Optimizing LLM Reasoning with Computational Tools
Source: MarkTechPost Reinforcement learning (RL) is a powerful technique for enhancing the reasoning capabilities of LLMs, enabling them...
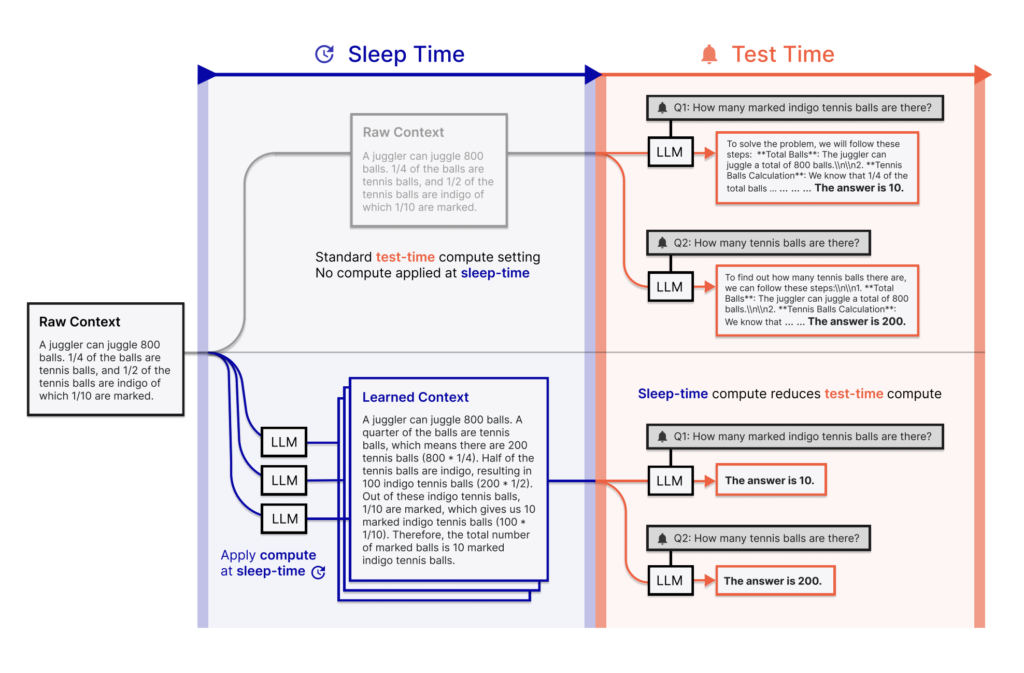
LLMs Can Think While Idle: Researchers from Letta and UC Berkeley Introduce ‘Sleep-Time Compute’ to Slash Inference Costs and Boost Accuracy Without Sacrificing Latency
Source: MarkTechPost Large language models (LLMs) have gained prominence for their ability to handle complex reasoning tasks, transforming...

LLMs Can Be Misled by Surprising Data: Google DeepMind Introduces New Techniques to Predict and Reduce Unintended Knowledge Contamination
Source: MarkTechPost Large language models (LLMs) are continually evolving by ingesting vast quantities of text data, enabling them...

Fourier Neural Operators Just Got a Turbo Boost: Researchers from UC Riverside Introduce TurboFNO, a Fully Fused FFT-GEMM-iFFT Kernel Achieving Up to 150% Speedup over PyTorch
Source: MarkTechPost Fourier Neural Operators (FNO) are powerful tools for learning partial differential equation solution operators, but lack...

Meta AI Introduces Collaborative Reasoner (Coral): An AI Framework Specifically Designed to Evaluate and Enhance Collaborative Reasoning Skills in LLMs
Source: MarkTechPost Rethinking the Problem of Collaboration in Language Models Large language models (LLMs) have demonstrated remarkable capabilities...

NVIDIA Introduces CLIMB: A Framework for Iterative Data Mixture Optimization in Language Model Pretraining
Source: MarkTechPost Challenges in Constructing Effective Pretraining Data Mixtures As large language models (LLMs) scale in size and...
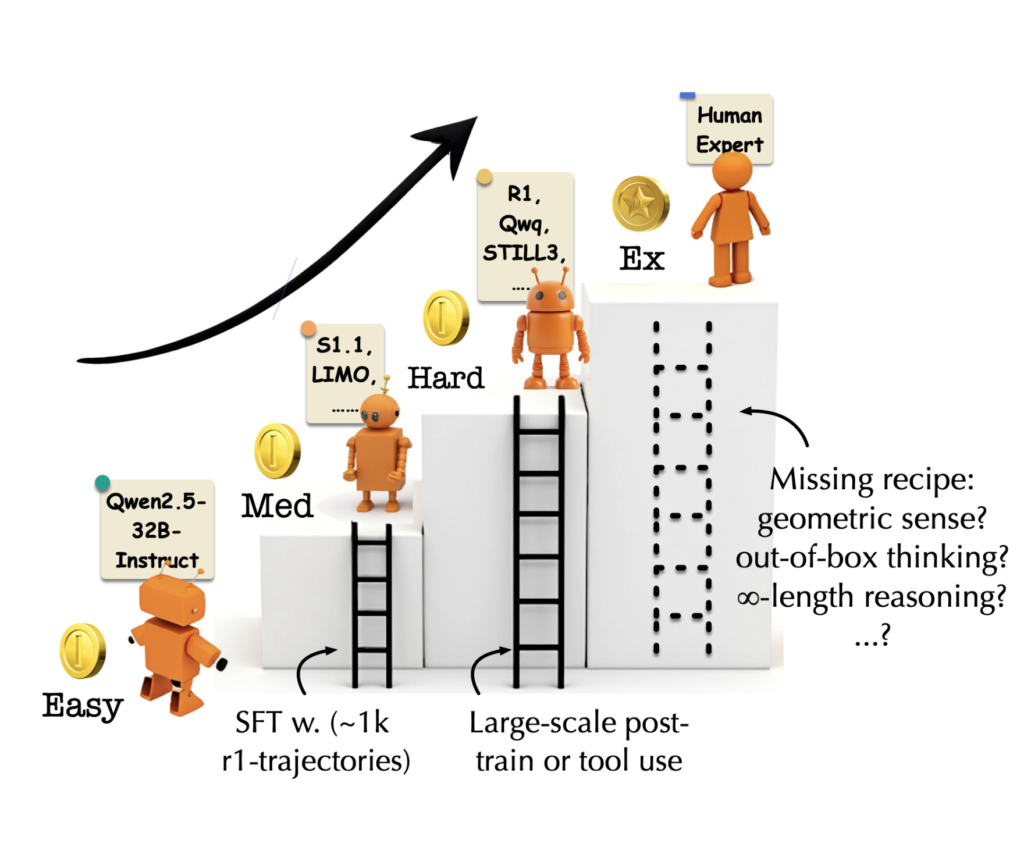
LLMs Can Now Solve Challenging Math Problems with Minimal Data: Researchers from UC Berkeley and Ai2 Unveil a Fine-Tuning Recipe That Unlocks Mathematical Reasoning Across Difficulty Levels
Source: MarkTechPost Language models have made significant strides in tackling reasoning tasks, with even small-scale supervised fine-tuning (SFT)...
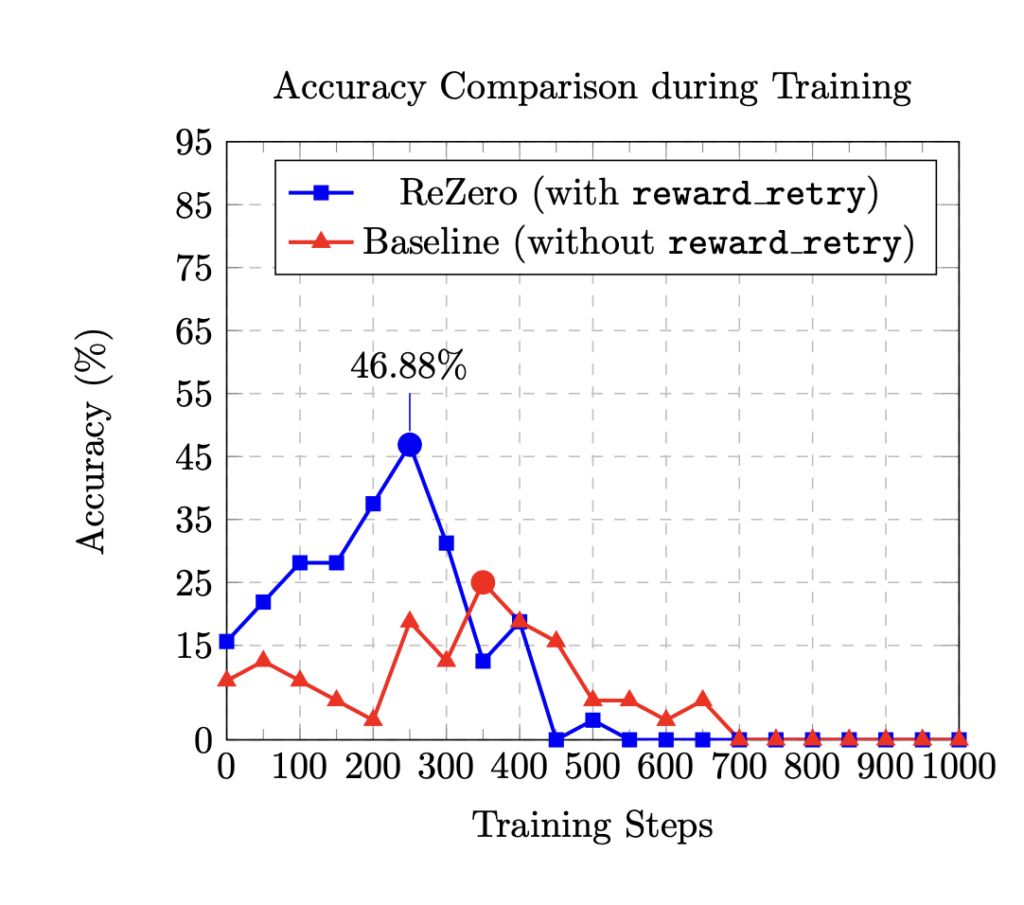
LLMs Can Now Learn to Try Again: Researchers from Menlo Introduce ReZero, a Reinforcement Learning Framework That Rewards Query Retrying to Improve Search-Based Reasoning in RAG Systems
Source: MarkTechPost The domain of LLMs has rapidly evolved to include tools that empower these models to integrate...

Meta AI Released the Perception Language Model (PLM): An Open and Reproducible Vision-Language Model to Tackle Challenging Visual Recognition Tasks
Source: MarkTechPost Despite rapid advances in vision-language modeling, much of the progress in this field has been shaped...