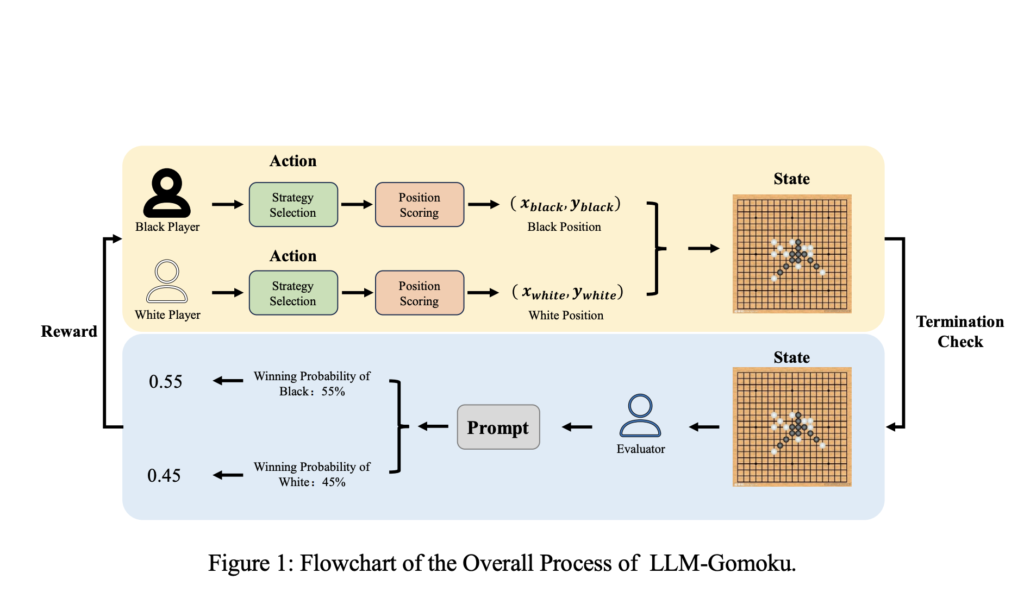
Enhancing Strategic Decision-Making in Gomoku Using Large Language Models and Reinforcement Learning
Source: MarkTechPost LLMs have significantly advanced NLP, demonstrating strong text generation, comprehension, and reasoning capabilities. These models have...
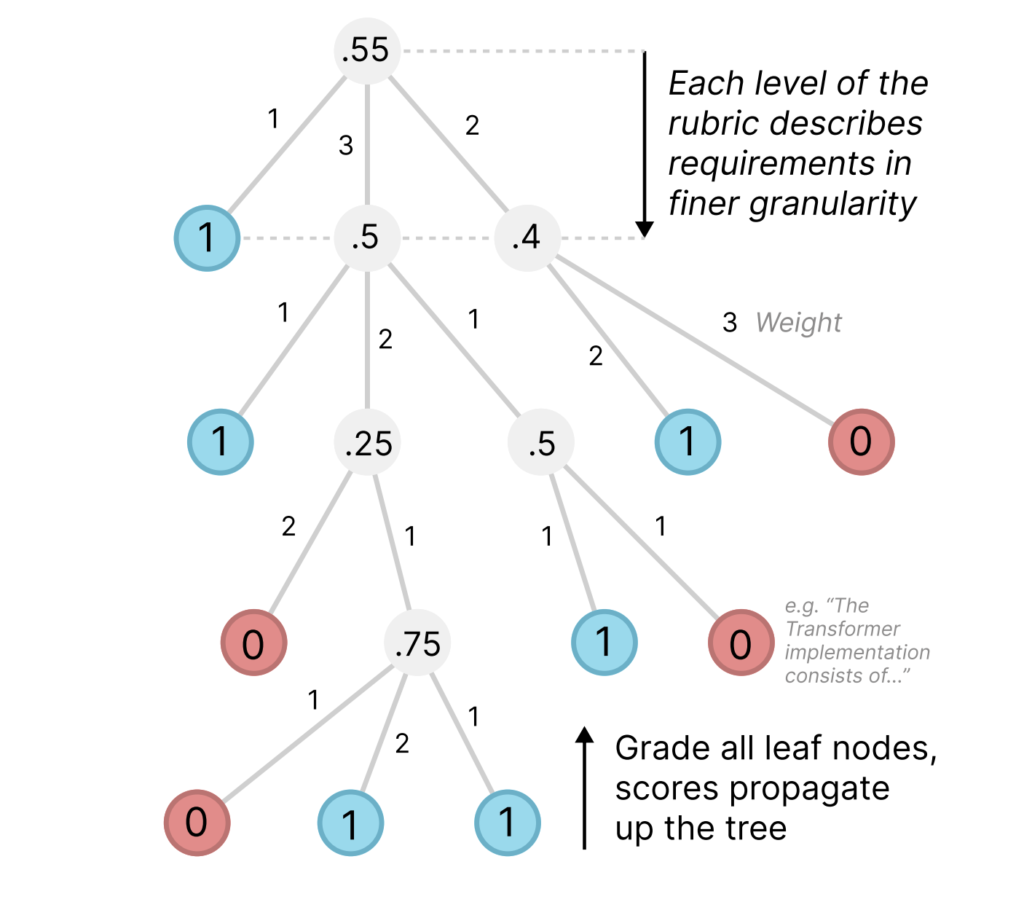
Open AI Releases PaperBench: A Challenging Benchmark for Assessing AI Agents’ Abilities to Replicate Cutting-Edge Machine Learning Research
Source: MarkTechPost The rapid progress in artificial intelligence (AI) and machine learning (ML) research underscores the importance of...
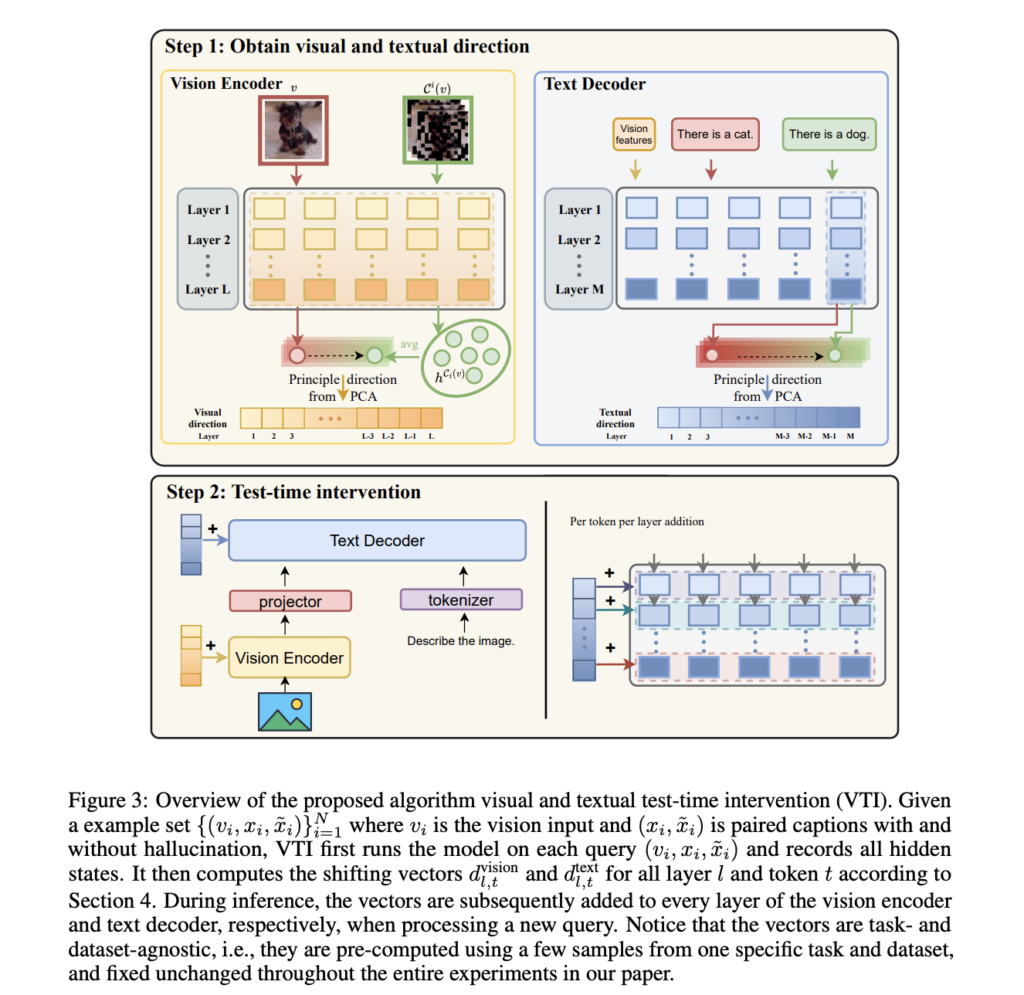
Mitigating Hallucinations in Large Vision-Language Models: A Latent Space Steering Approach
Source: MarkTechPost Hallucination remains a significant challenge in deploying Large Vision-Language Models (LVLMs), as these models often generate...
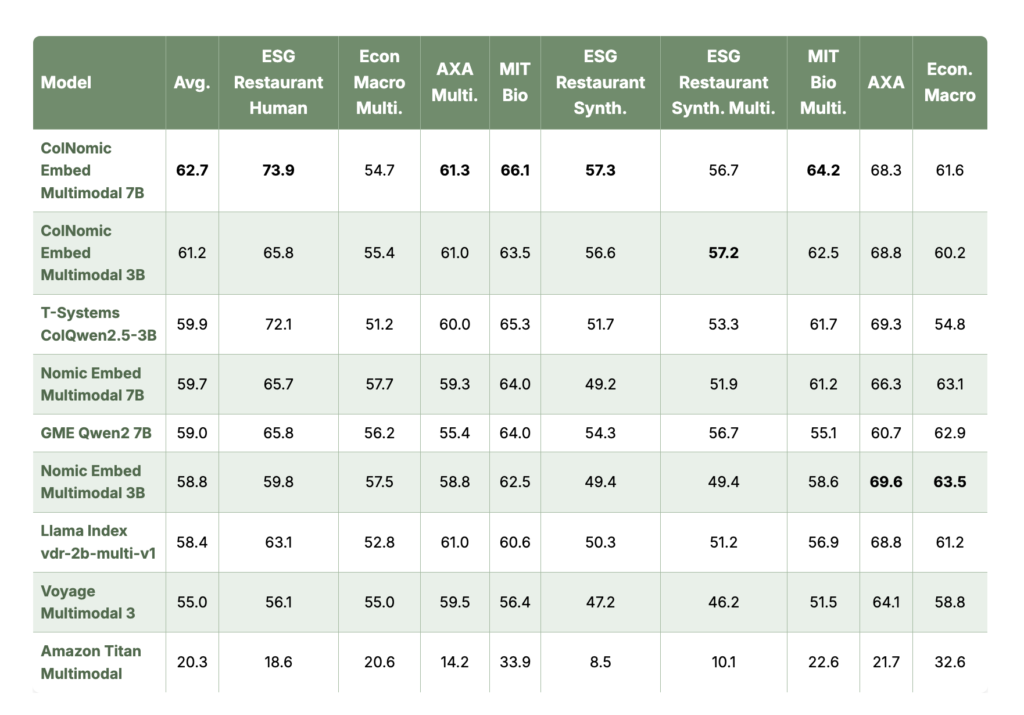
Nomic Open Sources State-of-the-Art Multimodal Embedding Model
Source: MarkTechPost Nomic has announced the release of “Nomic Embed Multimodal,” a groundbreaking embedding model that achieves state-of-the-art...
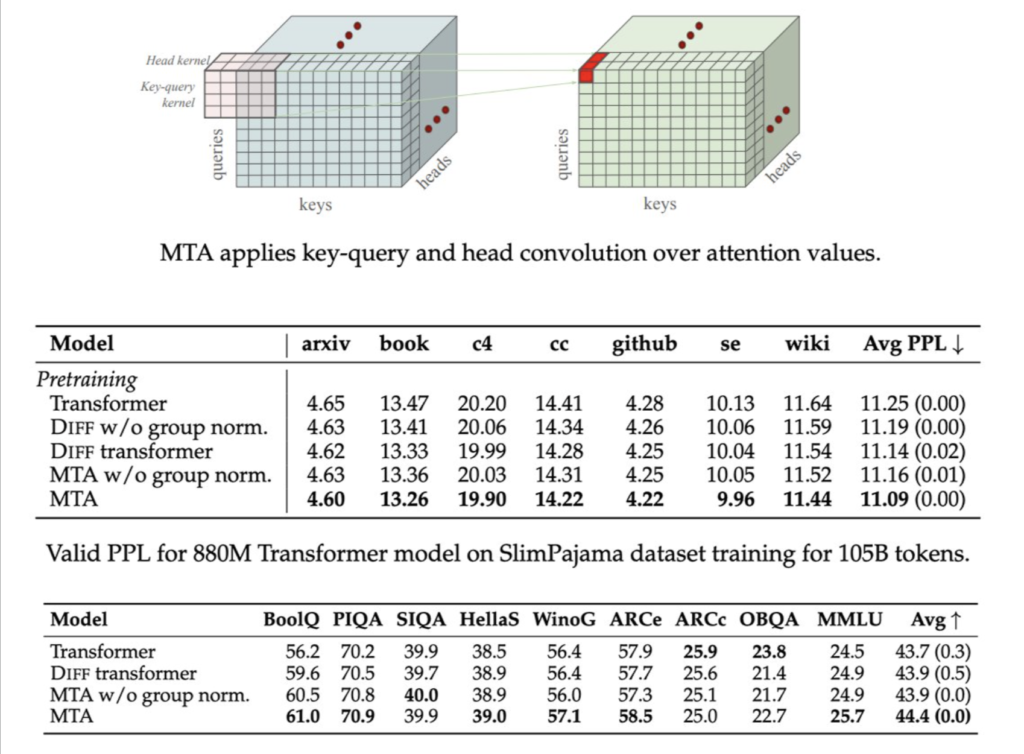
Meta AI Proposes Multi-Token Attention (MTA): A New Attention Method which Allows LLMs to Condition their Attention Weights on Multiple Query and Key Vectors
Source: MarkTechPost Large Language Models (LLMs) significantly benefit from attention mechanisms, enabling the effective retrieval of contextual information....

A Comprehensive Guide to LLM Routing: Tools and Frameworks
Source: MarkTechPost Deploying LLMs presents challenges, particularly in optimizing efficiency, managing computational costs, and ensuring high-quality performance. LLM...
Meet Amazon Nova Act: An AI Agent that can Automate Web Tasks
Source: MarkTechPost Amazon has revealed a new artificial intelligence (AI) model called Amazon Nova Act. This AI agent...
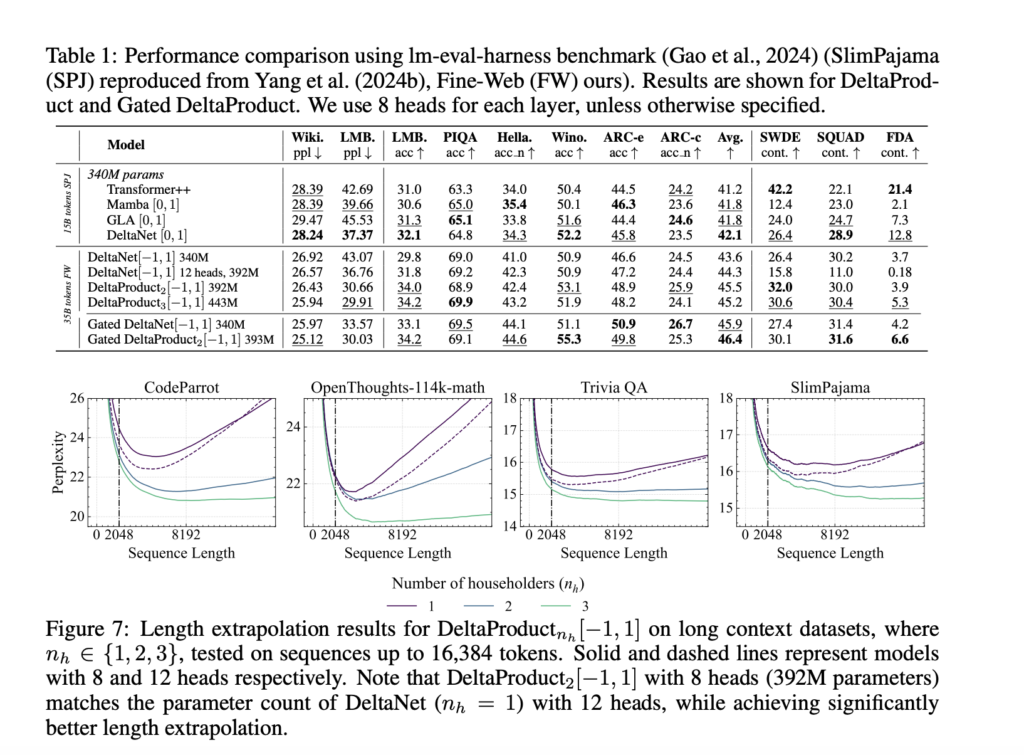
DeltaProduct: An AI Method that Balances Expressivity and Efficiency of the Recurrence Computation, Improving State-Tracking in Linear Recurrent Neural Networks
Source: MarkTechPost The Transformer architecture revolutionised natural language processing with its self-attention mechanism, enabling parallel computation and effective...

This AI Paper from ByteDance Introduces a Hybrid Reward System Combining Reasoning Task Verifiers (RTV) and a Generative Reward Model (GenRM) to Mitigate Reward Hacking
Source: MarkTechPost Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning LLMs with human values and preferences....

Meet ReSearch: A Novel AI Framework that Trains LLMs to Reason with Search via Reinforcement Learning without Using Any Supervised Data on Reasoning Steps
Source: MarkTechPost Large language models (LLMs) have demonstrated significant progress across various tasks, particularly in reasoning capabilities. However,...