Source: MarkTechPost
Most AI agents stop improving once a human stops tuning them. The model is fixed. The scaffold around it is fixed. Hexo Labs wants to move both at once. It released SIA (Self-Improving AI) this week as an open-source framework under an MIT license.
The core claim of this research is narrow but concrete. SIA edits both the agent’s scaffold and the model’s weights inside one self-improving loop.
What is SIA (Self-Improving AI)
SIA splits a task-specific agent into two parts. The first is the harness, also called the scaffold. That covers the system prompt, tool-dispatch logic, retry policy, and answer-extraction code. The second part is the model weights themselves.
Three LLM components drive the loop. A Meta-Agent writes the initial scaffold from a task specification and any reference code. A Task-Specific Agent runs the task and logs every step. A Feedback-Agent then reads that full trajectory and decides what to change.
That decision is the key idea. After each run, the Feedback-Agent picks one of two actions. It can rewrite the scaffold while weights stay fixed. Or it can trigger a weight update while the scaffold stays fixed.
The base model is openai/gpt-oss-120b. Weight updates use LoRA, a low-rank adapter, at rank 32. The Meta-Agent and Feedback-Agent both run on Claude Sonnet 4.6. Training runs on H100 GPUs through Modal, the team’s RL platform.
The research team labels its two operating points SIA-H and SIA-W+H. SIA-H uses harness updates only. SIA-W+H adds weight updates on top.
The Benchmark Case
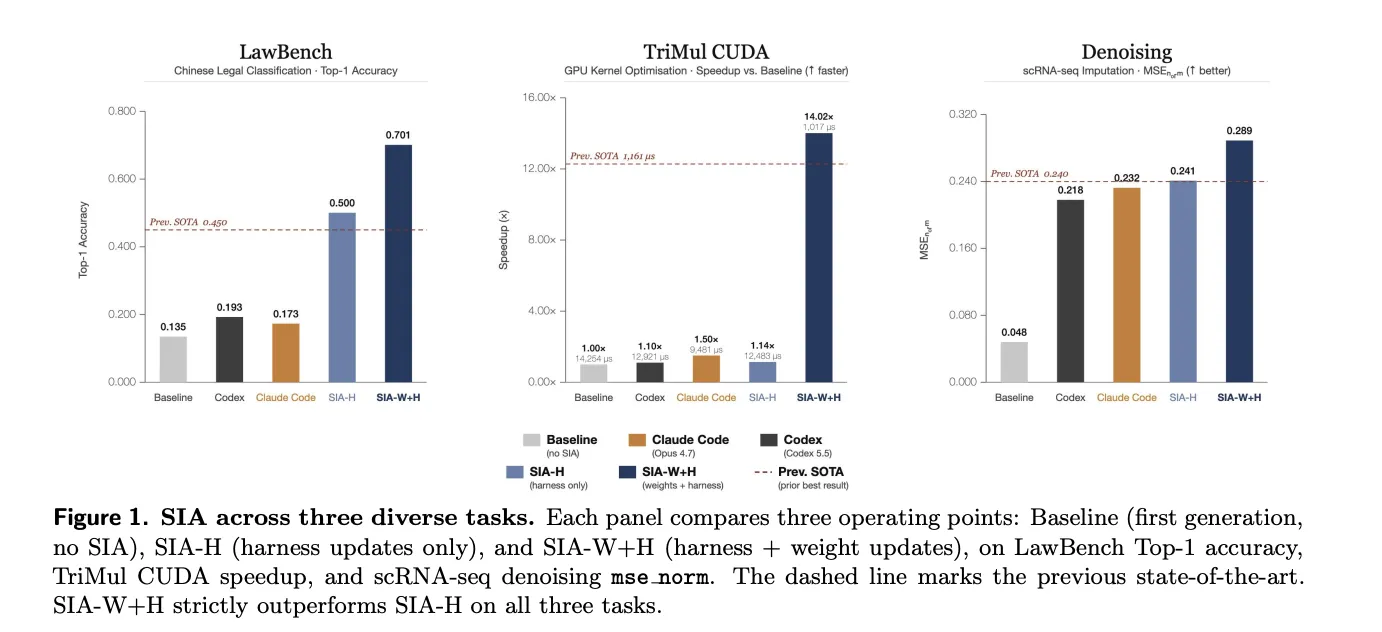
The research team tested SIA on three deliberately different domains. The pattern held across all three. Weight updates added gains beyond what scaffold editing alone reached. “Initial” is the base model through the Meta-Agent’s first scaffold, before any feedback.
| Task | Initial | Prev. SOTA | SIA-H (harness only) | SIA-W+H (harness + weights) |
|---|---|---|---|---|
| LawBench (top-1 acc) | 13.5% | 45.0% | 50.0% | 70.1% |
| AlphaEvolve TriMul (reward) | 0.105 | 1.292 | 0.120 | 1.475 |
| Denoising (mse_norm) | 0.048 | 0.240 | 0.241 | 0.289 |
On LawBench, the task is 191-class Chinese criminal charge classification. Harness iteration built a TF-IDF plus LinearSVC pipeline and plateaued at 50.0%. Weight updates via PPO then pushed accuracy to 70.1%. That is a 20.1 percentage-point gain over the harness-only best.
The TriMul task asks for a custom CUDA kernel on an H100 GPU. The kernel computes a core operation in AlphaFold2’s Evoformer module. Scaffold edits reached a 1.14× speedup over baseline. Weight updates then drove runtime from 12,483 to 1,017 microseconds. That is a 91.9% reduction from the harness-only peak.
One honest caveat appears in the same chart. The coding agent Claude Code reached 1.50× on TriMul unaided, beating SIA-H’s 1.14×. SIA-W+H still led overall at 14.02×.
For denoising, the agent tunes MAGIC, a single-cell RNA imputation method. Harness sweeps over its hyperparameters settled at 0.241 mse_norm. The first weight-update checkpoint added a two-line step that no scaffold produced. It rounded imputed counts to non-negative integers, lifting the score to 0.289.
How the Feedback-Agent Picks Its Move
SIA does not run one fixed RL recipe. The Feedback-Agent selects a training algorithm based on the reward signal it observes.
On LawBench, the reward was a clean outcome-based scalar, so it used PPO with GAE. On TriMul, most kernels failed to compile, so it used entropic advantage weighting. That method up-weights rare high-reward rollouts. On denoising, it used GRPO, which eliminates the value network entirely.
The research team also lists REINFORCE with KL-to-base, DPO, and best-of-N behavioural cloning. Each maps to a different reward shape and failure risk.
Strengths and What to Watch
Strengths:
- First system to edit both scaffold and weights in one loop, per the authors’ comparison table.
- Consistent gains over prior SOTA across three unrelated domains.
- Open source under MIT, installable as sia-agent, with four bundled tasks.
- Algorithm choice is conditioned on observed rewards, not a fixed schedule.
What to Watch:
- The research reports three tasks; broader algorithm-selection results are deferred.
- Both levers optimise the same fixed verifier, risking coupled Goodhart effects.
- The research warn the joint fixed point may be fragile under perturbation.
Marktechpost’s Visual Explainer
Hexo Labs · Open Source (MIT)
SIA: Self-Improving AI
Harness + Weight Updates
A self-improving loop that edits both an agent’s scaffold and its model weights, without further human tuning.
gpt-oss-120b LoRA rank 32 3 benchmarks Claude Sonnet 4.6 agents
The Gap
Two silos, operating in isolation
Harness school
Edit the scaffold
A meta-agent rewrites prompts, tools, and retry logic. The model weights stay fixed.
Test-time training
Edit the weights
An RL pipeline updates the model on task feedback. The harness stays fixed.
SIA closes the gap by moving both levers inside one loop.
Anatomy
What SIA actually is
- Harness (scaffold): the system prompt, tool-dispatch logic, retry policy, and answer-extraction code.
- Weights: the model’s own parameters, adapted with LoRA at rank 32.
- Three LLM components drive the loop: a Meta-Agent, a Task-Specific Agent, and a Feedback-Agent.
The Loop
One loop, two levers
After each run, the Feedback-Agent reads the full trajectory and picks one action.
Action A
Harness update
Rewrite the scaffold. Weights are held fixed.
Action B
Weight update
Train LoRA weights. The scaffold is held fixed.
The two levers interleave freely, not in locked sequential phases.
Evidence
Benchmark results
| Task | Initial | Prev. SOTA | SIA-H | SIA-W+H |
|---|---|---|---|---|
| LawBench (top-1 acc) | 13.5% | 45.0% | 50.0% | 70.1% |
| AlphaEvolve TriMul (reward) | 0.105 | 1.292 | 0.120 | 1.475 |
| Denoising (mse_norm) | 0.048 | 0.240 | 0.241 | 0.289 |
SIA-W+H (harness + weights) beat SIA-H (harness only) on all three tasks.
Mechanism
How the Feedback-Agent picks its move
- LawBench: a clean outcome-based reward, so it used PPO with GAE. Accuracy reached 70.1%.
- TriMul: most kernels fail to compile, so it used entropic advantage weighting. Runtime hit 1,017 µs.
- Denoising: it used GRPO, which eliminates the value network. Score rose to 0.289.
- Also available: REINFORCE + KL-to-base, DPO, and best-of-N behavioural cloning.
RQ2
What each lever changes
Harness
Externalised changes
Software-engineering improvements: new tools, tighter parsers, retry logic.
Weights
Internalised knowledge
Domain knowledge no prompt reaches: H100 kernel patterns, an integer-rounding step.
The harness shapes how the agent searches; weight updates change what the model knows.
The Honest Read
Limitations to keep in view
- Both levers optimise the same fixed verifier, risking a coupled co-evolutionary Goodhart effect.
- Fixed points can look strong on the verifier yet stay fragile under perturbation.
- The paper reports three tasks; broader algorithm-selection results are deferred.
- A separate 350× superintelligence claim in launch coverage does not appear in the paper.
Get Started
Run it yourself
Open source under MIT at hexo-ai/sia. Built on gpt-oss-120b with LoRA rank 32.
# install the Claude backend pip install 'sia-agent[claude]' export ANTHROPIC_API_KEY="..." # run 5 self-improvement generations on a bundled task sia --task lawbench --max_gen 5 --run_id 1Four bundled tasks ship in the box: gpqa, lawbench, longcot-chess, spaceship-titanic.
Source: Hebbar et al., SIA: Self Improving AI with Harness & Weight Updates (arXiv:2605.27276) github.com/hexo-ai/sia
Key Takeaways
- SIA is the first self-improving loop that edits both an agent’s scaffold and its model weights.
- A Feedback-Agent reads each run’s full trajectory, then picks a harness rewrite or weight update.
- Combining both levers beat scaffold-only on all three tasks: LawBench, TriMul kernels, scRNA-seq denoising.
- Harness edits add software-engineering hygiene; weight updates surface domain knowledge no prompt reaches.
- Open source under MIT (hexo-ai/sia), built on gpt-oss-120b with LoRA rank 32.
Check out the Repo and Research Paper. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us