
Qwen Team Releases Qwen3-Coder-Next: An Open-Weight Language Model Designed Specifically for Coding Agents and Local Development
Source: MarkTechPost Qwen team has just released Qwen3-Coder-Next, an open-weight language model designed for coding agents and local...

NVIDIA AI Brings Nemotron-3-Nano-30B to NVFP4 with Quantization Aware Distillation (QAD) for Efficient Reasoning Inference
Source: MarkTechPost NVIDIA has released Nemotron-Nano-3-30B-A3B-NVFP4, a production checkpoint that runs a 30B parameter reasoning model in 4...
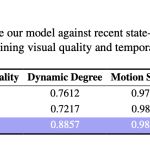
Robbyant Open Sources LingBot World: a Real Time World Model for Interactive Simulation and Embodied AI
Source: MarkTechPost Robbyant, the embodied AI unit inside Ant Group, has open sourced LingBot-World, a large scale world...
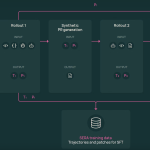
AI2 Releases SERA, Soft Verified Coding Agents Built with Supervised Training Only for Practical Repository Level Automation Workflows
Source: MarkTechPost Allen Institute for AI (AI2) Researchers introduce SERA, Soft Verified Efficient Repository Agents, as a coding...

A Coding Implementation to Training, Optimizing, Evaluating, and Interpreting Knowledge Graph Embeddings with PyKEEN
Source: MarkTechPost In this tutorial, we walk through an end-to-end, advanced workflow for knowledge graph embeddings using PyKEEN,...
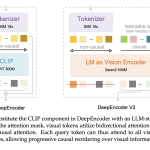
DeepSeek AI Releases DeepSeek-OCR 2 with Causal Visual Flow Encoder for Layout Aware Document Understanding
Source: MarkTechPost DeepSeek AI released DeepSeek-OCR 2, an open source document OCR and understanding system that restructures its...

A Coding Deep Dive into Differentiable Computer Vision with Kornia Using Geometry Optimization, LoFTR Matching, and GPU Augmentations
Source: MarkTechPost We implement an advanced, end-to-end Kornia tutorial and demonstrate how modern, differentiable computer vision can be...

Ant Group Releases LingBot-VLA, A Vision Language Action Foundation Model For Real World Robot Manipulation
Source: MarkTechPost How do you build a single vision language action model that can control many different dual...

Beyond the Chatbox: Generative UI, AG-UI, and the Stack Behind Agent-Driven Interfaces
Source: MarkTechPost Most AI applications still showcase the model as a chat box. That interface is simple, but...

Google DeepMind Unveils AlphaGenome: A Unified Sequence-to-Function Model Using Hybrid Transformers and U-Nets to Decode the Human Genome
Source: MarkTechPost Google DeepMind is expanding its biological toolkit beyond the world of protein folding. After the success...