
FlashLabs Researchers Release Chroma 1.0: A 4B Real Time Speech Dialogue Model With Personalized Voice Cloning
Source: MarkTechPost Chroma 1.0 is a real time speech to speech dialogue model that takes audio as input...
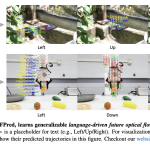
Salesforce AI Introduces FOFPred: A Language-Driven Future Optical Flow Prediction Framework that Enables Improved Robot Control and Video Generation
Source: MarkTechPost Salesforce AI research team present FOFPred, a language driven future optical flow prediction framework that connects...
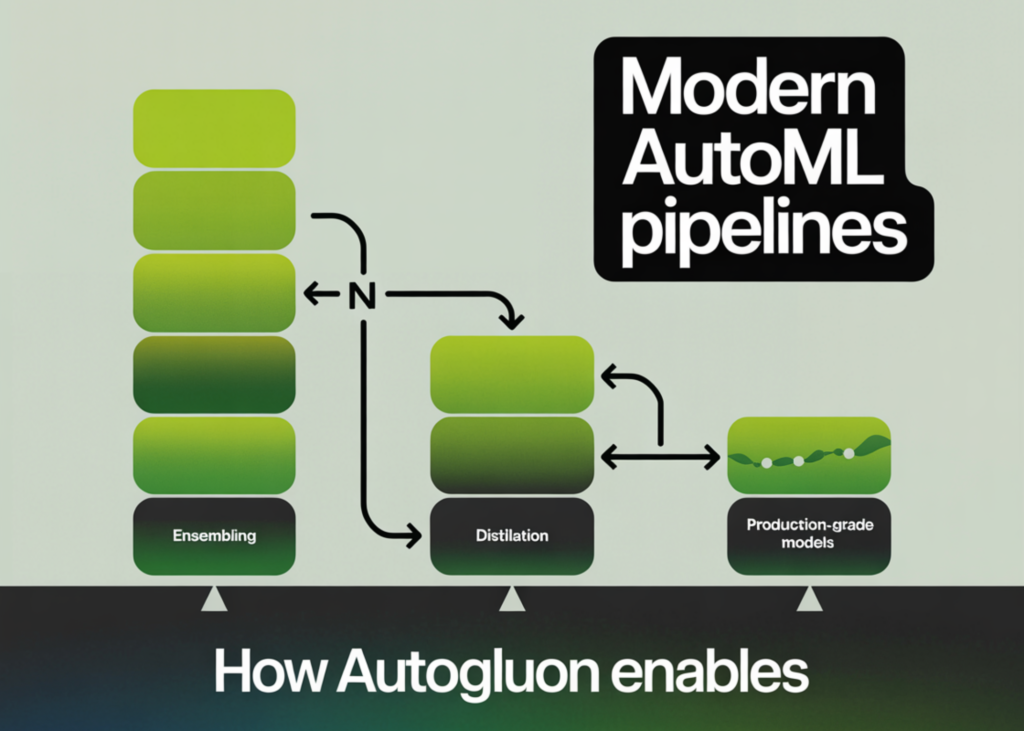
How AutoGluon Enables Modern AutoML Pipelines for Production-Grade Tabular Models with Ensembling and Distillation
Source: MarkTechPost In this tutorial, we build a production-grade tabular machine learning pipeline using AutoGluon, taking a real-world...
Liquid AI Releases LFM2.5-1.2B-Thinking: a 1.2B Parameter Reasoning Model That Fits Under 1 GB On-Device
Source: MarkTechPost Liquid AI has released LFM2.5-1.2B-Thinking, a 1.2 billion parameter reasoning model that runs fully on device...
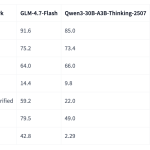
Zhipu AI Releases GLM-4.7-Flash: A 30B-A3B MoE Model for Efficient Local Coding and Agents
Source: MarkTechPost GLM-4.7-Flash is a new member of the GLM 4.7 family and targets developers who want strong...

Microsoft Research Releases OptiMind: A 20B Parameter Model that Turns Natural Language into Solver Ready Optimization Models
Source: MarkTechPost Microsoft Research has released OptiMind, an AI based system that converts natural language descriptions of complex...
Vercel Releases Agent Skills: A Package Manager For AI Coding Agents With 10 Years of React and Next.js Optimisation Rules
Source: MarkTechPost Vercel has released agent-skills, a collection of skills that turns best practice playbooks into reusable skills...
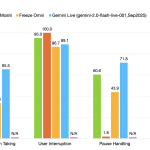
NVIDIA Releases PersonaPlex-7B-v1: A Real-Time Speech-to-Speech Model Designed for Natural and Full-Duplex Conversations
Source: MarkTechPost NVIDIA Researchers released PersonaPlex-7B-v1, a full duplex speech to speech conversational model that targets natural voice...
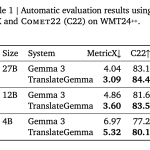
Google AI Releases TranslateGemma: A New Family of Open Translation Models Built on Gemma 3 with Support for 55 Languages
Source: MarkTechPost Google AI has released TranslateGemma, a suite of open machine translation models built on Gemma 3...

NVIDIA AI Open-Sourced KVzap: A SOTA KV Cache Pruning Method that Delivers near-Lossless 2x-4x Compression
Source: MarkTechPost As context lengths move into tens and hundreds of thousands of tokens, the key value cache...